DORA - Median Time to Restore Service
What is this metric?
The time to restore service after service incidents, rollbacks, or any type of production failure happened.
Why is it important?
This metric is essential to measure the disaster control capability of your team and the robustness of the software.
Which dashboard(s) does it exist in
DORA dashboard. See live demo.
How is it calculated?
MTTR = Total incident age (in hours)/number of incidents.
If you have three incidents that happened in the given data range, one lasting 1 hour, one lasting 2 hours and one lasting 3 hours. Your MTTR will be: (1 + 2 + 3) / 3 = 2 hours.
Below are the benchmarks for different development teams from Google's report. However, it's difficult to tell which group a team falls into when the team's median time to restore service is between one week and six months. Therefore, DevLake provides its own benchmarks to address this problem:
| Groups | Benchmarks | DevLake Benchmarks |
|---|---|---|
| Elite performers | Less than one hour | Less than one hour |
| High performers | Less one day | Less than one day |
| Medium performers | Between one day and one week | Between one day and one week |
| Low performers | More than six months | More than one week |
Source: 2021 Accelerate State of DevOps, Google
Data Sources RequiredDeploymentsfrom Jenkins, GitLab CI, GitHub Action, BitBucket Pipelines, or Webhook, etc.Incidentsfrom Jira issues, GitHub issues, TAPD issues, PagerDuty Incidents, etc.
Define deployment and incident in data transformations while configuring the blueprint of a project to let DevLake know what CI/issue records can be regarded as deployments or incidents.
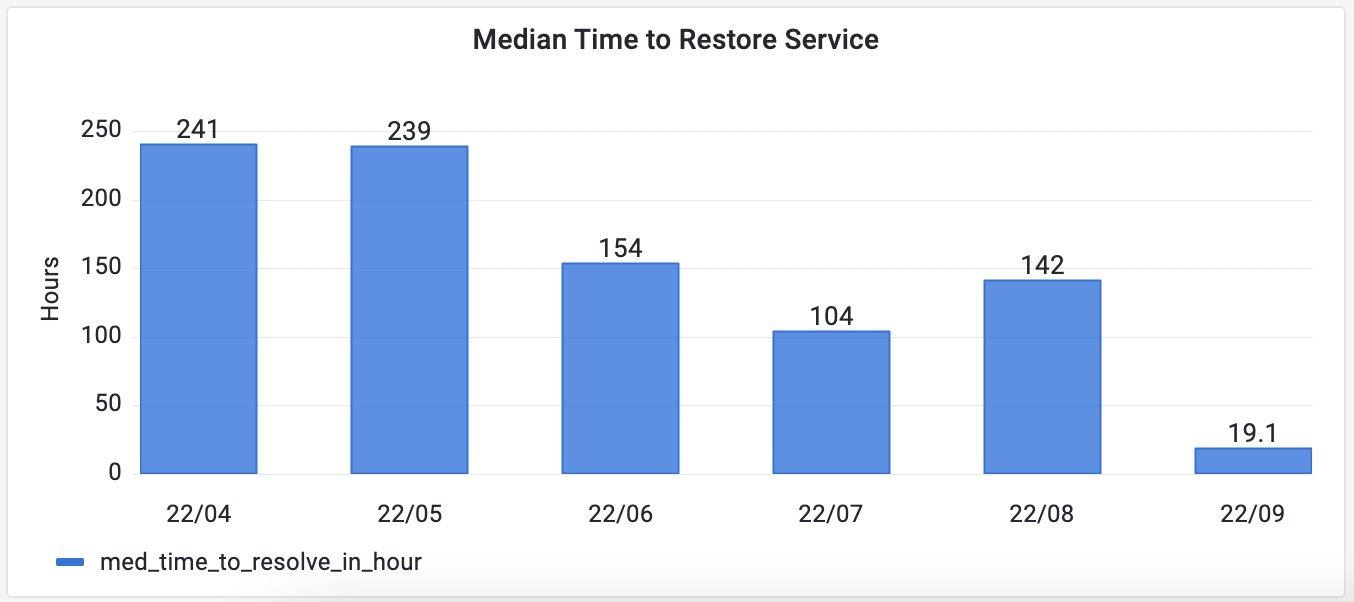
If you want to measure the monthly trend of the Median Time to Restore Service as the picture shown below, run the following SQL in Grafana.
with _incidents as (
-- get the number of incidents created each month
SELECT
distinct i.id,
date_format(i.created_date,'%y/%m') as month,
cast(lead_time_minutes as signed) as lead_time_minutes
FROM
issues i
join board_issues bi on i.id = bi.issue_id
join boards b on bi.board_id = b.id
join project_mapping pm on b.id = pm.row_id
WHERE
pm.project_name in ($project)
and i.type = 'INCIDENT'
and i.lead_time_minutes is not null
),
_find_median_mttr_each_month_ranks as(
SELECT *, percent_rank() over(PARTITION BY month order by lead_time_minutes) as ranks
FROM _incidents
),
_mttr as(
SELECT month, max(lead_time_minutes) as median_time_to_resolve
FROM _find_median_mttr_each_month_ranks
WHERE ranks <= 0.5
GROUP BY month
),
_calendar_months as(
-- deal with the month with no incidents
SELECT date_format(CAST((SYSDATE()-INTERVAL (month_index) MONTH) AS date), '%y/%m') as month
FROM ( SELECT 0 month_index
UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3
UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6
UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9
UNION ALL SELECT 10 UNION ALL SELECT 11
) month_index
WHERE (SYSDATE()-INTERVAL (month_index) MONTH) > SYSDATE()-INTERVAL 6 MONTH
)
SELECT
cm.month,
case
when m.median_time_to_resolve is null then 0
else m.median_time_to_resolve/60 end as median_time_to_resolve_in_hour
FROM
_calendar_months cm
left join _mttr m on cm.month = m.month
ORDER BY 1
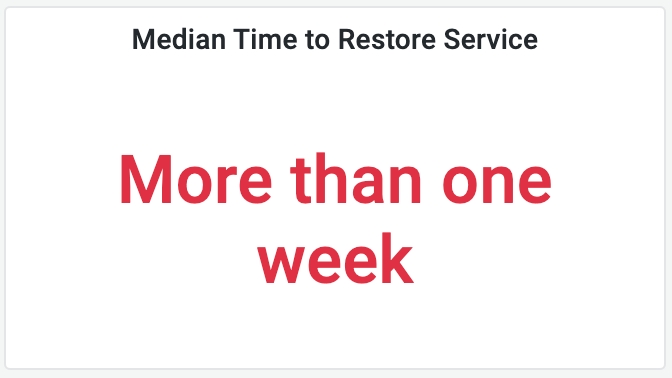
If you want to measure in which category your team falls into as in the picture shown below, run the following SQL in Grafana.
with _incidents as (
-- get the incidents created within the selected time period in the top-right corner
SELECT
distinct i.id,
cast(lead_time_minutes as signed) as lead_time_minutes
FROM
issues i
join board_issues bi on i.id = bi.issue_id
join boards b on bi.board_id = b.id
join project_mapping pm on b.id = pm.row_id
WHERE
pm.project_name in ($project)
and i.type = 'INCIDENT'
and $__timeFilter(i.created_date)
),
_median_mttr_ranks as(
SELECT *, percent_rank() over(order by lead_time_minutes) as ranks
FROM _incidents
),
_median_mttr as(
SELECT max(lead_time_minutes) as median_time_to_resolve
FROM _median_mttr_ranks
WHERE ranks <= 0.5
)
SELECT
case
WHEN median_time_to_resolve < 60 then "Less than one hour"
WHEN median_time_to_resolve < 24 * 60 then "Less than one Day"
WHEN median_time_to_resolve < 7 * 24 * 60 then "Between one day and one week"
WHEN median_time_to_resolve >= 7 * 24 * 60 then "More than one week"
ELSE "N/A.Please check if you have collected deployments/incidents."
END as median_time_to_resolve
FROM
_median_mttr
How to improve?
- Use automated tools to quickly report failure
- Prioritize recovery when a failure happens
- Establish a go-to action plan to respond to failures immediately
- Reduce the deployment time for failure-fixing